

At first glance, the robots.txt file might look like something reserved for only the most text-savvy among us. But actually, learning how to use a robots.txt file is something anybody can and should master.
And if you’re interested in having precision control over which areas of your website allow access to search engine robots (and which ones you can keep off-limits), then this is the resource you need.
In this guide, we’re going to go over the fundamental basics, including:
- What a robots.txt file is
- When to use the robots.txt file
- How to create a robots.txt file
- Why and how to implement a robots.txt “Disallow All” (or “Allow All”)
What is a Robots.txt File?
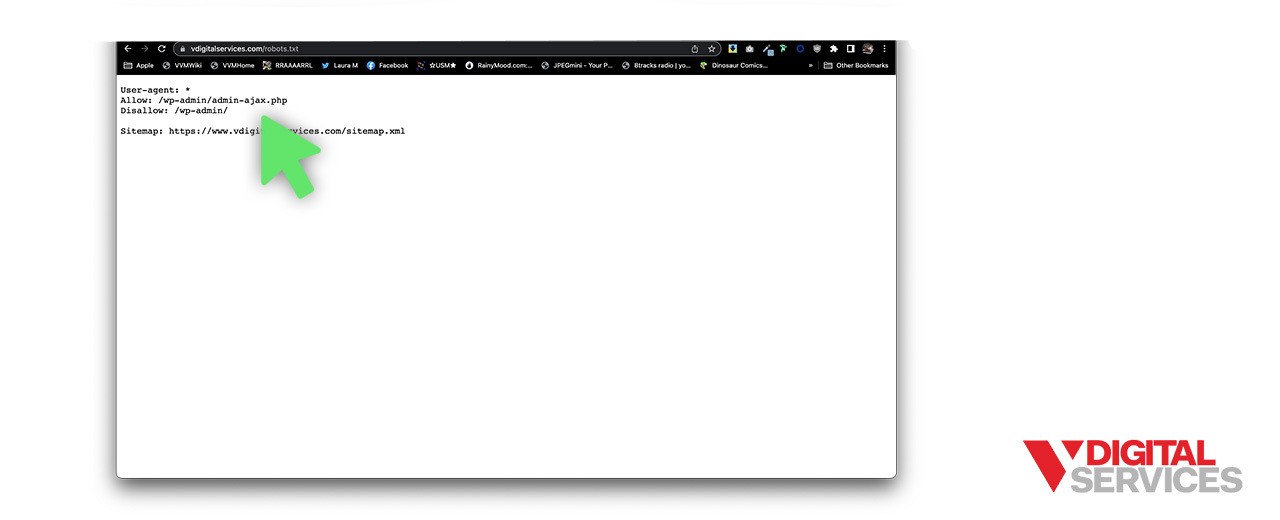
In simplest terms, robots.txt is a special text file located on your website’s root domain and used to communicate with search engine robots. The text file specifies which webpages/folders within a given website they are permitted to access.
You might want to block URLs in robots.txt to prevent search engines from indexing specific webpages that you don’t want online users to access. For example, a “Disallow” robots.txt file might forbid access to webpages containing expired special offers, unreleased products, or private, internal-only content.
When it comes to resolving duplicate content problems, or other similar issues, using the robots.txt file to disallow access can also support your SEO efforts.
Exactly how does a robots.txt file work? When a search engine robot begins crawling your website, it first checks to see if there is a robots.txt file in place. If one exists, the search engine robot can “understand” which of the pages they are not allowed to access, and they will only view permitted pages.
When to Use a Robots.txt File
The primary reason for using a robots.txt file is to block search engines (Google, Bing, etc.) from indexing specific webpages or content.
These types of files can be an ideal option if you want to:
- Manage crawl traffic (if you’re concerned that your server is being overwhelmed)
- Ensure that certain parts of your website are kept private (for example, admin pages or the “sandbox” pages belonging to the development team)
- Avoid problems with indexation
- Block a URL
- Prevent duplicate content from being included in search results (and negatively impacting SEO)
- Stop search engines from indexing certain files, such as PDFs or images
- Remove media files from SERPs (search engine results pages)
- Run paid advertisements or links that require you to meet specific requirements for robots
As you can see, there are many reasons to use a robots.txt file. However, if you want search engines to access and index your website in its entirety, then there is no need for a robots.txt file.
How to Set Up a Robots.txt File
1. Check if your website already has a robots.txt file in place.
First, let’s ensure that there’s not an existing robots.txt file for your website. In the URL bar of your web browser, add “/robots.txt” to the end of your domain name (like this – www.example.com/robots.txt).
If a blank page appears, you do not have a robots.txt file. But if a file with a list of instructions shows up, then there is one.
2. If you are creating a new robots.txt file, determine your overall goal.
One of the most significant benefits to robots.txt files is that they simplify allowing or disallowing multiple pages at one time without requiring that you manually access each page’s code.
There are three basic options for robots.txt files, each one with a specific outcome:
- Full allow: Search engine robots are allowed to crawl all content (note that because all URLs are allowed by default, a full allow is generally unnecessary)
- Full disallow: Search engine robots are not allowed to crawl any content (you want to block Google’s crawlers from accessing any part of your site)
- Conditional allow: The file establishes rules for blocked content and which is open to crawlers (you want to disallow certain URLs, but not your entire website)
Once you pinpoint your desired purpose, you’re ready to set up the file.
3. Use a robots.txt file to block selected URLs.
When you create a robots.txt file, there are two key elements you’ll be working with:
- The user-agent is the specific search engine robot that the URL block applies.
- The disallow line addresses the URL(s) or files you want to block from the search engine robot.
These lines include a single entry within the robots.txt file, which means that one robots.txt file can contain multiple entries.
You can use the user-agent line to name a specific search engine bot (such as Google’s Googlebot), or you can use an asterisk (*) to indicate that the block should apply to all search engines: User-agent: *
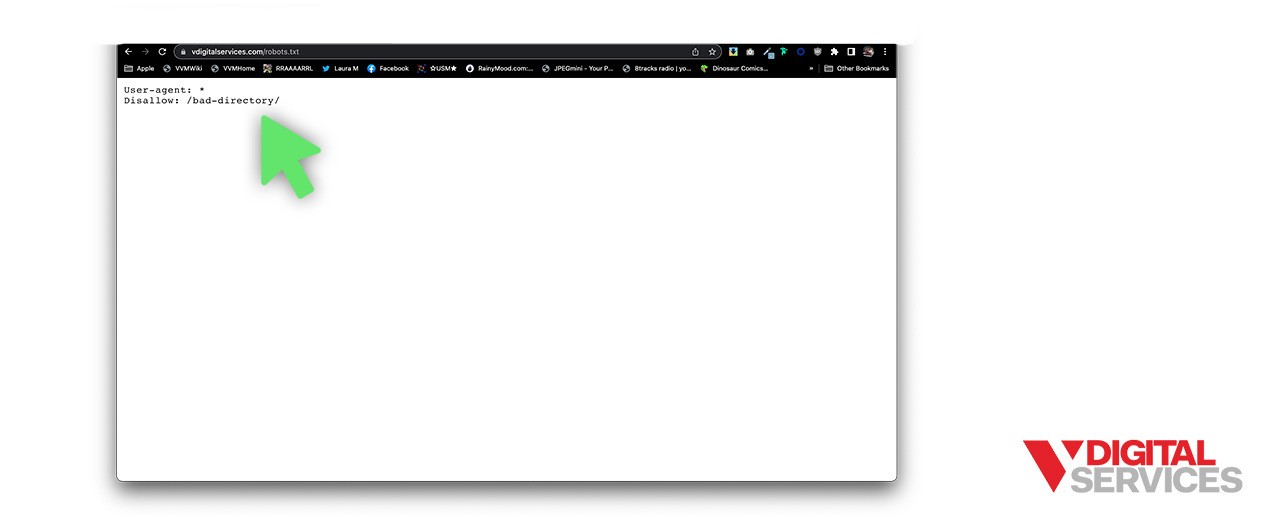
Then, the disallow line will break down exactly what access is restricted. A forward slash (Disallow: /) blocks the entire website. Or, you can use a forward slash followed by a specific page, image, file type, or directory. For example, Disallow: /bad-directory/ will block the website directory and its contents, while Disallow: /secret.html blocks a webpage.
Put it all together, and you may have an entry that looks something like this:
User-agent: *
Disallow: /bad-directory/
Every URL you want to Allow or Disallow needs to be situated on its own line. If you include multiple URLs on a single line, you can run into issues when crawlers cannot separate them.
You can find a wide variety of example entries in this resource from Google if you’d like to see some other potential options.
4. Save the robots.txt file.
Once finished with your entries, you’ll need to save the file properly.
Here’s how:
- Copy it into a text or notepad file, then Save As “robots.txt.” Use only lowercase letters.
- Save the file in the highest-level directory of your website. Ensure it’s placed in the root domain and that its name matches “robots.txt.”
- Add the file to your website code’s top-level directory so that it can be easily crawled and indexed.
- Confirm that your code follows the proper structure (User-agent -> Disallow/Allow -> Host -> Sitemap). That way, search engine robots will access the pages in the right order.
- You’ll need to set up separate files for different subdomains. For example, “blog.domain.com” and “domain.com” require individual files.
6. Test the robots.txt file.
Finally, run a quick test in the Google Search Console to ensure your robots.txt file is working as it should.
- Open up the Tester tool, then do a quick scan to see if you spot any errors or warning messages.
- If everything looks good, enter a URL to test in the box located at the bottom of the page.
- Choose the user agent you want to test (from the drop-down menu).
- Click “TEST.”
- The “TEST” button will then read “ACCEPTED” or “BLOCKED,” which tells you whether or not that file is blocked from crawler access.
- If needed, you can edit the file and retest it. Don’t forget that any edits made in the tool must be copied to your website code and saved there.

When You Should Not Use the Robots.txt File
Now, you know how to use robots.txt to Disallow to Allow access – but when should you avoid it?
According to Google, robots.txt shouldn’t be your go-to method for blocking URLs without rhyme or reason. This method for blocking isn’t a substitute for proper website development and structure, and it’s certainly not an acceptable stand-in for security measures. Google offers some reasons to use various methods for blocking crawlers, so you can decide which one best fits your needs.

Refine Your SEO Strategy and Website Design the Right Way with V Digital Services
You’ve learned that there are some situations in which the robots.txt file can be incredibly useful. However, there are also more than a few scenarios that don’t call for a robots.txt file – and you can even accidentally create an unintentional ripple effect.
With help from the expert web development and design team at V Digital Services, you can make sure your website checks all the right boxes: SEO, usability, aesthetics, and more. We’ll work with you to find the ideal solutions for any current challenges and strategize innovative ways to pursue new goals in the future. Whether you’re still confused about the robots.txt file, or you’re simply ready to get professional web development support, V Digital Services is your go-to team for all things digital marketing.
Get started when you contact our team today!
Photo credits: BEST-BACKGROUNDS, REDPIXEL.PL, Elle Aon, SFIO CRACHO\
Article updated February 29, 2024